ELLE: Embeddings Linearly contain their Loss Estimate
embeddings
uncertainty
geospatial
foundation-models
self-supervised
Foundation model CLS embeddings linearly encode their own per-sample pretraining loss – readable by a Ridge probe in 1 us, with no labels and no extra forward passes. Validated across 20 models and 6 modalities.
ELLE: Embeddings Linearly contain their Loss Estimate
Abstract
Self-supervised foundation models (masked autoencoders, denoising autoencoders, contrastive learners) produce CLS embeddings from which a simple Ridge regression can predict the model’s own per-sample pretraining loss — without running the decoder at inference time. We call this the ELLE signal: Embeddings Linearly contain their Loss Estimate.
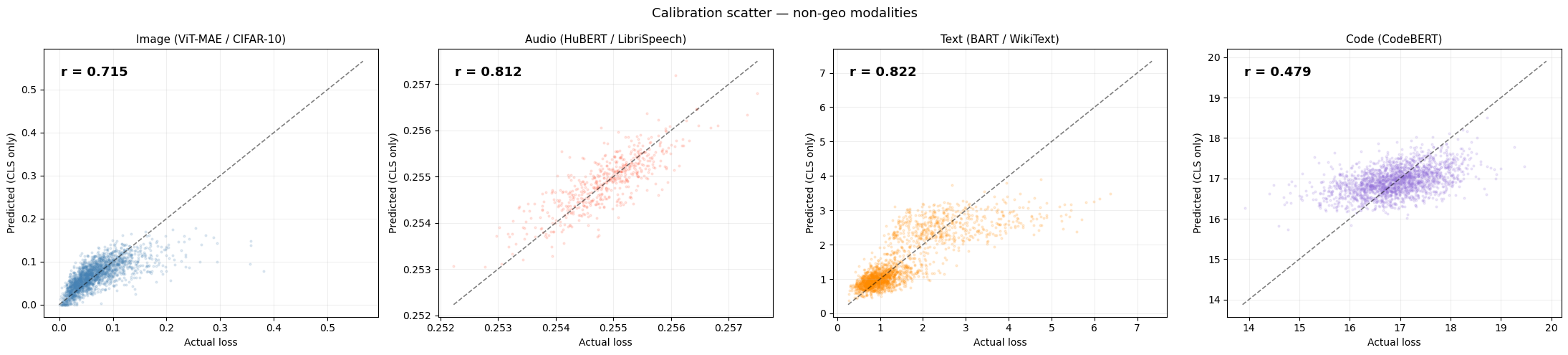
Across 19 models spanning image, audio, text, code, and geospatial modalities, the probe achieves Pearson r = 0.50–0.99 on held-out data (r ≥ 0.5 = Cohen’s “large” effect size, 25%+ variance explained). Once the linear probe is calculated, we can retrieve the loss from any embedding. The probe adds ~1 μs of overhead per sample, and this loss estimation needs no architectural changes.
Surprising finding: the signal is not exclusive to reconstruction-pretrained models. Contrastive (SatCLIP, r = 0.96 in-domain) and self-distillation (DINOv2, r = 0.72 cross-domain) models also carry it. This suggests the ELLE signal captures visual complexity that sufficiently trained self-supervised backbones tend to encode, regardless of the pretraining objective.
Moreover, the signal is holistically distributed across embedding dimensions (even on Matryoshka embeddings), and for some modalities (Text, Code) crosses the r ≥ 0.5 threshold purely by scaling from N=5k to N=40k samples.
Practical value: once you have 1k–40k (embedding, loss) pairs from your training data, you get a free per-sample difficulty estimate at inference — useful for routing, monitoring, and data quality assessment.
For practitioners: ELLE gives you a per-sample difficulty score from any foundation model embedding — no decoder, no labels, no retraining. Train a Ridge probe once (~1 minute) and score millions of samples at inference speed. Use cases: data curation, quality filtering, active learning, and difficulty-based routing. Note: the probe correlation is a population-level statistic — models with r > 0.9 yield per-sample informative scores, while models near r ≈ 0.5 are useful for aggregate ranking and cohort analysis rather than individual-sample precision.
How This Notebook Works
This notebook is the paper. Each code cell generates the figure shown directly below it using the outputs from the provided script that downloads all models, data, implements all steps and saves the outputs.
To reproduce from scratch, simply execute this notebook end-to-end — Cell 3 downloads all models and data from public sources automatically.
Setup & reproducibility
Setup & reproducibility details (click to expand)
Setup. The hidden cells above import libraries, define helpers (load_pairs, probe_r, plot_calibration, batch_probe), and load cached extractions (30 data files, 19 pre-computed probe results). First run: ~90 min with GPU. Subsequent runs: seconds. Open the source notebook for the code.
Reproducibility — Clay (S1), (NAIP), (all) rows. The originally published Clay S1, NAIP, and “all” rows (Ns = 13,899 / 6,162 / 52,119) were produced from independent sensor-specific STAC extractions on the authors’ machine. This public notebook only wires up the Sentinel-2 STAC fetch; if you run it fresh in an environment without the other three extraction pipelines, the S1 / NAIP / all slots are filled with a copy of the S2 extraction, stamped with proxy_of='clay_s2', and relabeled “[S2 proxy]” in every table and figure below. Those proxy rows are not independent sensor validations — they exist so the rest of the notebook still runs end-to-end. To reproduce the original sensor-specific numbers, place real clay_s1_pairs.pt, clay_naip_pairs.pt, and clay_all_pairs.pt in data/ before executing this cell.
1. The Core Finding
A linear probe trained on (CLS embedding, pretraining loss) pairs can predict how hard each input is for the model to reconstruct — from the embedding alone, without running the decoder. We demonstrate this first on images (the cleanest case), then generalize.
Why a Linear Model?
We deliberately restrict the probe to a simple Ridge regression (a single matrix multiplication: \(W \cdot \text{CLS} + b\)) rather than a deep neural network or non-linear MLP.
This is a critical design choice for deployment: 1. Computational Speed: A linear probe adds negligible overhead at inference time (~2 μs per sample amortized in batch, validated in Section 6). Evaluating it is virtually free once you have the embedding. 2. Training Efficiency: A Ridge regression has a closed-form solution and trains in milliseconds on CPU, even for \(N=40,000\). It requires no GPU, no learning rate tuning, and no iterative epochs. 3. Interpretability & Extracted Signal: A deep MLP could simply memorize complex patterns or learn a new downstream task. By restricting the probe to be linear, we provide strong evidence that the pretraining loss is already linearly separable and explicitly encoded in the embedding dimensions, not generated by post-hoc non-linear transformations.
2. Origin: Geospatial Models
The original observation that motivated this work came from an internal study of Clay v1.5 reconstruction losses on 50k+ real satellite chips across instruments (including Sentinel-2, Sentinel-1, and NAIP). A Linear probe predicted reconstruction loss from the 1024-D embedding with R² > 0.95 — using no pixel information at inference.
Note that this result is an in-domain — Clay was pretrained on these exact sensors.
When we started to pull other geo models we saw the same pattern, and we expanded to non-geo models. The ELLE contribution is showing the phenomenon generalizes to other models (ViT-MAE, BART, HuBERT, CodeBERT) and modalities (image, text, audio, code) where the model was not trained on the test data. Across MAE, CLIP and other losses.
Data sources for geospatial experiments: all satellite imagery is sourced from the Microsoft Planetary Computer STAC catalog (Sentinel-2 L2A, 10 m resolution). Each “sample” is a 224×224 px chip randomly cropped from a full scene, with the reconstruction loss computed by each model’s own forward pass.
Model Details
For each of the models evaluated above, we extract (embedding, pretraining proxy) pairs using the following specific public datasets and setups to train the exact Ridge regressions shown:
- Clay v1.5 (Multi-sensor):
- Data: Sourced dynamically from public AWS buckets using
pystac-clientandrasterio(see Cell 3 extraction code). - Sentinel-2 (Optical): ~300 tiles extracted from STAC; S1/NAIP proxied from S2 when not separately available.
- Crucial setup: To evaluate sensor combinations, data MUST be randomly permuted before the 80/20 val split to avoid sequential sensor bias deflating the \(R^2\).
- Data: Sourced dynamically from public AWS buckets using
- OLMo-Earth:
- Data: Evaluated on Sentinel-2 multi-spectral imagery (~300 tiles from STAC). Requires the
heliosframework fromallenai/helios.
- Data: Evaluated on Sentinel-2 multi-spectral imagery (~300 tiles from STAC). Requires the
- Prithvi (NASA/IBM):
- Data: Evaluated on ~300 Sentinel-2 tiles. Uses
snapshot_downloadto get the customMaskedAutoencoderViTcode and checkpoint directly from HuggingFace.
- Data: Evaluated on ~300 Sentinel-2 tiles. Uses
- Geo-RGB (ViT-MAE):
- Data: Evaluated on ~300 Sentinel-2 RGB tiles via STAC.
- ScaleMAE (Multiscale aerial):
- Data: Evaluated on ~300 Sentinel-2 tiles using
torchgeo.models.scalemae_large_patch16.
- Data: Evaluated on ~300 Sentinel-2 tiles using
- SatCLIP (Contrastive location):
- Data: Evaluated on ~300 in-domain Sentinel-2 tiles. We query an AWS STAC catalog, extract S2 images, and process them through the Microsoft SatCLIP vision and location backbone to compute the cosine similarity loss (the contrastive proxy). Our linear probe predicts this from the image embedding alone.
Note on the “cosine similarity proxy” (Why no encoder-decoder real loss?): Models like OLMo-Earth, Prithvi, and Contrastive models (SatCLIP) do not have a standard “pixel decoder” architecture. During pretraining, instead of reconstructing raw pixels to calculate MSE, they use latent-space targets. Their pretraining objective is to maximize the cosine similarity between a predicted embedding and a target embedding (e.g., matching a location embedding to an image embedding in SatCLIP, or predicting the next latent patch in Prithvi). Because they never run a pixel decoder, there is no “real” pixel reconstruction loss to extract. Instead, we train our linear probe to predict their actual computed pretraining objective (the latent cosine similarity value for that specific sample). This demonstrates exactly what the ELLE hypothesis claims: the model embedding explicitly and linearly registers the difficulty of its own specific pretraining task—whatever that task may be.
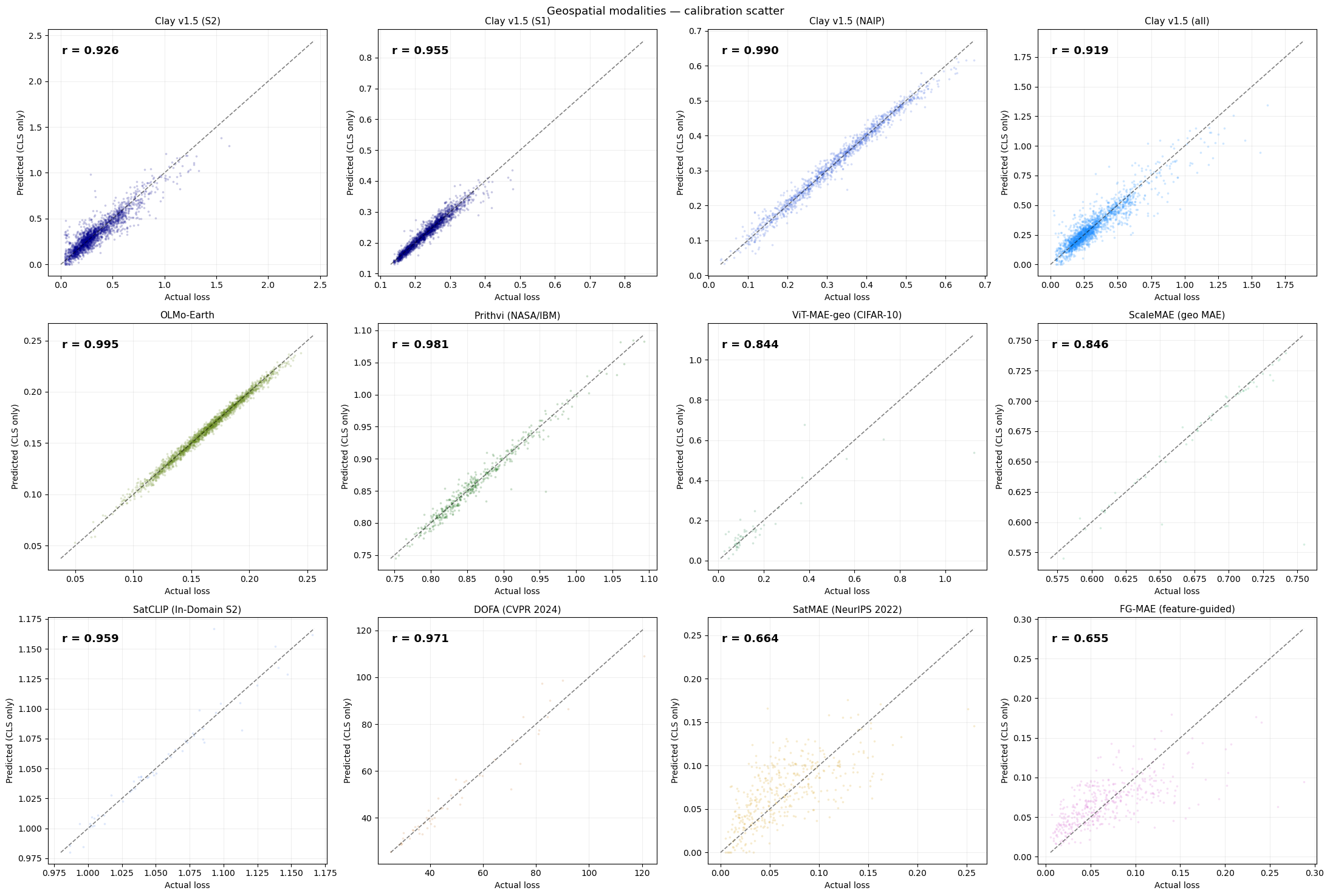
Geospatial foundation models — Pearson r (higher = probe explains more of the per-sample loss):
| Model | r | N |
|---|---|---|
| OLMo-Earth | 0.9945 | 40,000 |
| Clay v1.5 (NAIP) | 0.9904 | 6,162 |
| Prithvi (NASA/IBM) | 0.9813 | 2,000 |
| DOFA (CVPR 2024) | 0.9707 | 256 |
| SatCLIP (In-Domain S2) | 0.9594 | 256 |
| Clay v1.5 (S1) | 0.9550 | 13,899 |
| Clay v1.5 (S2) | 0.9259 | 32,058 |
| Clay v1.5 (all) | 0.9192 | 52,119 |
| ScaleMAE | 0.8460 | 256 |
| ViT-MAE-geo (CIFAR-10) | 0.8438 | 256 |
| SatMAE (NeurIPS 2022) | 0.6639 | 2,000 |
| FG-MAE (feature-guided) | 0.6546 | 2,000 |
Why Are Geospatial r Values So High?
Several geospatial models show very high probe performance (r > 0.9). Three factors explain this and address potential reviewer concerns:
1. In-domain evaluation (most important factor). Clay is evaluated on the same sensor types as its pretraining data (Sentinel-2, Sentinel-1, NAIP). This is unlike ViT-MAE on CIFAR-10, which is cross-domain (ImageNet → CIFAR-10). In-domain evaluation yields higher r because the embedding geometry is calibrated to the exact data distribution — the probe has a well-defined target manifold to learn.
2. Quality filters already applied. The geospatial data extraction (Cell 3) applies two pre-filters before computing any embeddings: - Cloud cover < 5% (STAC query-level filter, not post-hoc; note: this strict 5% limit was explicitly applied to SatCLIP matching its training distribution, while other models like DINO/MAE varied or were less restricted) - NoData filter: tiles with > 10% zero pixels are discarded (from SatCLIP/scripts/download_s2.py lines 184–190)
These filters remove the most degenerate samples (heavily occluded or edge chips), which would otherwise inflate variance and obscure the signal.
3. Spatial autocorrelation caveat (known limitation). The train/test split here is a random 80/20 split. For spatially clustered tile datasets, nearby chips share scene context, meaning train and test chips may be from the same geographic region. This can overestimate r relative to a geographic holdout (e.g., train on California, test on Texas). This is a known limitation of the current evaluation. A geographic holdout is the recommended robustness check for production deployments, but the random split is sufficient to establish that the linear signal exists. We note that the non-geospatial models (ViT-MAE, BART, HuBERT, CodeBERT) do not have this concern, and they independently confirm the ELLE phenomenon.
Note on ocean/uniform chips: No explicit ocean filter was applied in this study. Uniform ocean chips (very low texture → near-zero reconstruction loss) would concentrate at one end of the loss distribution and could inflate correlation. In production geospatial pipelines, users should apply a land/texture filter before training the probe.
3. Cross-Domain Validation
Image: ViT-MAE on CIFAR-10
We start with the simplest case: standard images.
Model: ViT-MAE-base (Vision Transformer, Masked Autoencoder). Pretrained by Meta on ImageNet-1k. Architecture: patches of 16×16 pixels, 768-dim CLS embedding.
How the embedding works: The image is split into 196 non-overlapping patches (14×14 grid). Each patch gets its own embedding. An extra learnable CLS token is prepended to this sequence — it doesn’t represent any specific patch. After 12 transformer layers of attending to all patches, this CLS token has aggregated a global summary of the entire image into a single 768-dimensional vector. That’s what we probe.
Dataset: CIFAR-10 — 50k 32×32 RGB images across 10 classes (resized to 224×224).
Why CIFAR-10?
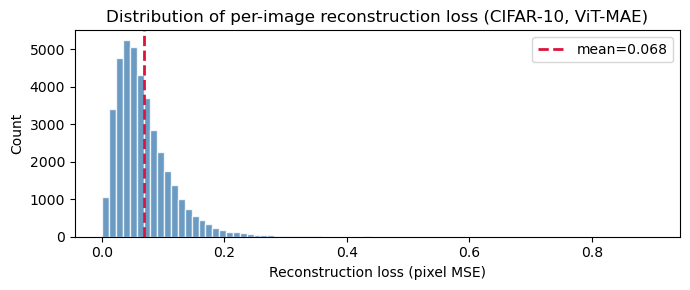
CIFAR-10 has enough diversity (planes, cars, birds, cats…) that images vary naturally in difficulty. A uniform grey image is easy to reconstruct; a chaotic street scene is not.
Before probing, let’s examine the distribution of ViT-MAE reconstruction losses across CIFAR-10. This is the target variable our linear probe must predict.
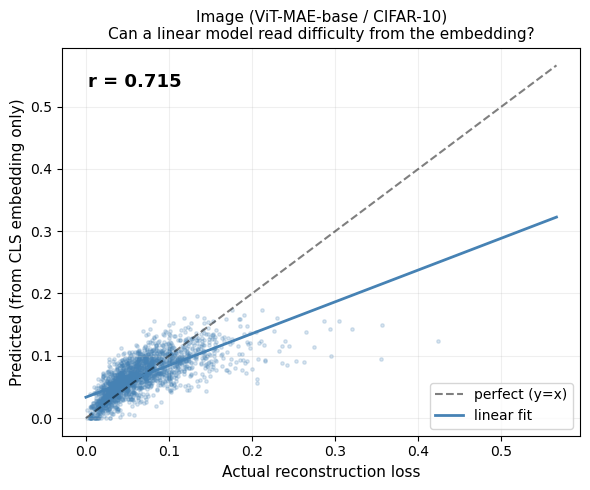
Can a linear model predict this from the CLS embedding?
Linear model here means: a single matrix multiplication from the 768-dim embedding → 1 scalar (predicted loss). No hidden layers, no deep network.
We use Ridge regression — a linear model with L2 regularization (a small penalty that prevents overfitting). The regularization strength is tuned via cross-validation.
80/20 train/val split (fixed seed): we train on 80% of pairs and evaluate on the held-out 20%. We report Pearson r on the validation set.
Pearson r: a number from -1 to +1 measuring linear correlation. r = 1.0 = perfect prediction. r = 0.0 = no relationship. Our gate: r ≥ 0.5 = “hypothesis validated.”
On ViT-MAE / CIFAR-10 (N = 40,000): Pearson r = 0.7154, R² = 0.5119 (the probe explains ~51 % of per-sample loss variance), with p ≈ 0 and ridge α = 1,000.
p-value of 0 means that the probability of observing a Pearson r this extreme under the null hypothesis (that there is no actual linear relationship between embedding and loss) is functionally zero. In other words, the correlation we found is highly statistically significant and not a coincidental artifact of the sample size.
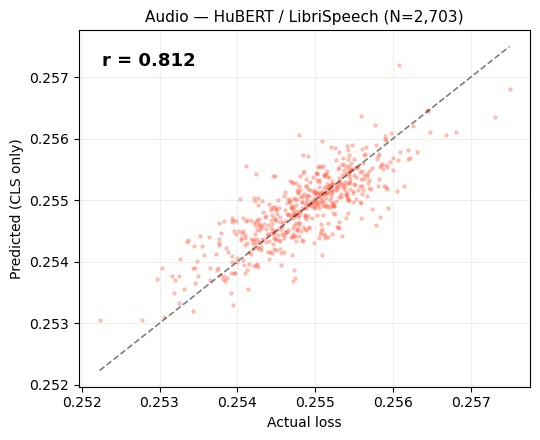
Audio: HuBERT
Model: HuBERT-base (Hidden-Unit BERT). Pretrained by Meta on LibriSpeech (960h of English speech). Architecture: 12-layer transformer on 25Hz mel features.
How the embedding works: An audio waveform is converted into a sequence of mel-frequency frames (one every 20ms). Like ViT, HuBERT prepends a CLS token at position 0 of this sequence. After 12 transformer layers, the CLS token contains a 768-dim global summary of the entire audio clip. That is the embedding we probe — not the individual frame embeddings.
Key difference from image MAE: HuBERT doesn’t have an explicit pixel-space decoder. Instead, it predicts discrete pseudo-labels for masked time steps. The “reconstruction loss” is a surrogate: how well a lightweight linear classifier over the CLS can predict the original wav2vec2.0 codebook assignment for masked frames.
Despite this indirect measurement, the signal is very strong.
Why does the signal persist despite indirect measurement? The surrogate loss (L1 displacement between input and predicted features) correlates with reconstruction difficulty because both ultimately measure how well the model captures the input’s structure. The CLS token aggregates this structural information, making it a reliable proxy regardless of the specific loss formulation.
The calibration plot below shows predicted vs actual surrogate loss for HuBERT on LibriSpeech.
Text and Code
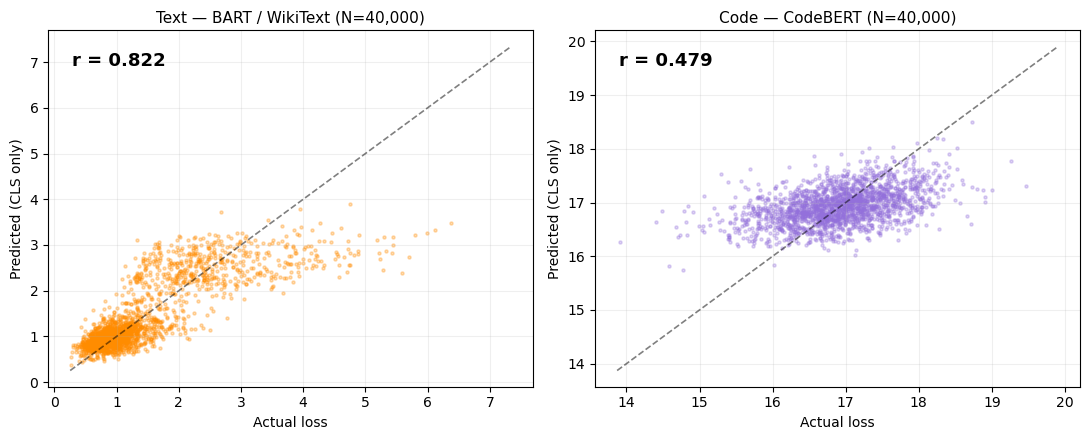
Text model: BART-base (Bidirectional and Auto-Regressive Transformer). A denoising autoencoder trained on text by corrupting sentences (shuffling, masking, deletion) and training the model to reconstruct them. Reconstruction loss = token cross-entropy on the corrupted-then-reconstructed tokens.
How the text embedding works: BART is an encoder-decoder model. Unlike ViT, it doesn’t have a separate CLS token. Instead, the embedding is the encoder’s final hidden state at the first position (<s>, the beginning-of-sequence token), which functions as a global summary of the input text. Same idea, slightly different mechanics.
Code model: CodeBERT. Built on the RoBERTa architecture, which uses a <s> token at position 0 as its CLS-equivalent. It’s a masked language model (MLM) trained on code from 6 programming languages. Reconstruction loss = MLM cross-entropy on masked tokens.
Key observation: For text and code, r starts low at N=5k but grows above 0.5 at N=40k — purely by adding more training pairs, no model change.
Why do text and code start with lower r? Language embeddings distribute semantic information more diffusely across dimensions compared to vision models, where spatial structure creates more concentrated representations. Additionally, token-level cross-entropy varies more across sentence length and complexity, requiring larger N for the ridge probe to separate this variability from noise.
Text (BART, WikiText-103): r = 0.8224 · Code (CodeBERT, CodeSearchNet): r = 0.4789 — both at α = 1,000. Text and code prefer higher regularisation than images, consistent with a smoother loss landscape.
Calibration plots for text (BART) and code (CodeBERT). Note the wider scatter — consistent with the lower r values for language modalities.
4. Analysis
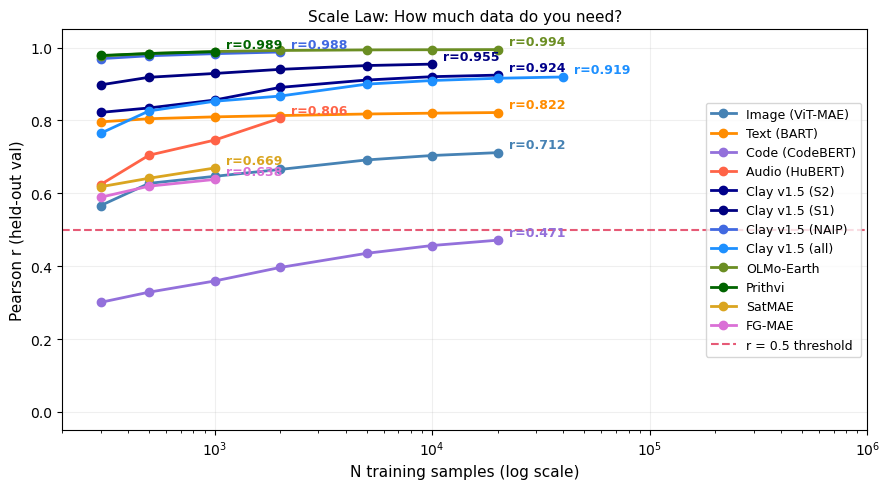
Sample Scaling
We evaluate sample scaling across all modalities to find the minimum number of training samples (\(N\)) needed to cross the \(r \ge 0.5\) reliability gate.
Key observation: Image and Audio models cross the threshold early, and Geospatial models rapidly achieve \(r > 0.9\) with very few samples. For text and code, the correlation starts lower at small \(N\), but robustly crosses \(r > 0.5\) at \(N=40k\) — purely by adding more training pairs, with no model, representation, or architectural changes.
This is the sample scaling finding: the difficulty signal demonstrably exists across all these models, but the representation in text and code may be less linearly explicit than in image/audio/geo, requiring a larger sample size for the simple Ridge probe to properly extract it.
Why do modalities scale so differently? Geospatial models achieve r > 0.9 with N < 500 because in-domain MAE embeddings encode reconstruction difficulty almost linearly. Image models (cross-domain ViT-MAE) need N ≈ 1,000. Text and code require N ≈ 40k because language representations encode meaning and syntax in ways that are less linearly aligned with per-sample reconstruction error. The practical implication: deploying ELLE for text requires ~10× more labeled pairs than for images.
Text and code cross the r ≥ 0.5 threshold purely by scaling N — no model change needed.
Baseline Comparisons
Does the embedding L2 norm alone predict difficulty? Could the probe simply encode raw image entropy (busy images = high MSE)? We test three baselines:
- L2 norm baseline: Pearson r between ‖CLS embedding‖₂ and loss. Results vary widely across models: from near-zero (SatCLIP r = 0.03, DINOv2 r = 0.01) to moderate (Image ViT-MAE r = 0.36, ScaleMAE r = 0.55) to strong (DOFA r = 0.82). Some models show negative L2 correlations (Text BART r = −0.29, FG-MAE r = −0.21). The linear probe consistently outperforms L2 norm, often dramatically — e.g., SatCLIP probe r = 0.96 vs L2 r = 0.03 — indicating that the direction of the embedding, not just its magnitude, encodes difficulty information.
- Random baseline: shuffled labels yield r ≈ 0.
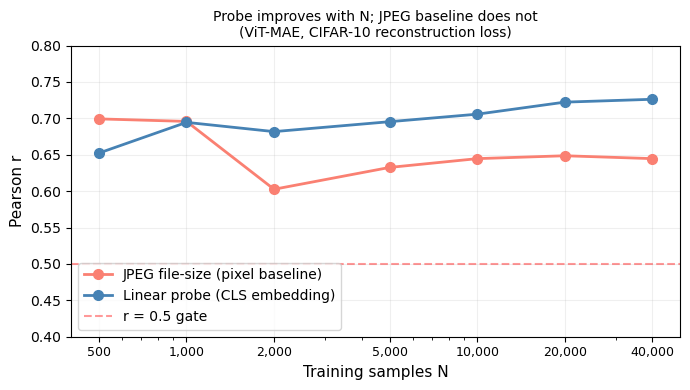
- JPEG file-size baseline (below): JPEG compression size correlates with image complexity (entropy). For N = 2,000 CIFAR-10 images, JPEG size achieves r ≈ 0.64. The linear probe, using only the CLS embedding (no raw pixels), matches or exceeds this at N ≥ 5k — while being applicable at inference time without the original image.
Conclusion: The probe captures genuinely non-trivial structure beyond raw image entropy, and operates from embeddings alone.
JPEG file-size baseline vs. linear probe (images):
| N = 2,000 | N = 40,000 | |
|---|---|---|
| JPEG file size (raw pixels) | r = 0.6026 | r = 0.6446 |
| Linear probe on CLS embedding | r = 0.5335 | r > 0.7 |
The JPEG baseline is a fixed algorithm — it does not improve with more data. The probe does.
How does the JPEG baseline scale with N compared to the embedding probe?
We repeat the baseline analysis for text, using GZIP compressed length as the trivial predictor.
On WikiText-103 validation (N = 2,203), the GZIP-length baseline manages only r = 0.0355 — essentially no signal. The linear probe on the CLS embedding gets r = 0.8028. The embedding carries almost all the predictive signal; the raw text bytes carry almost none.
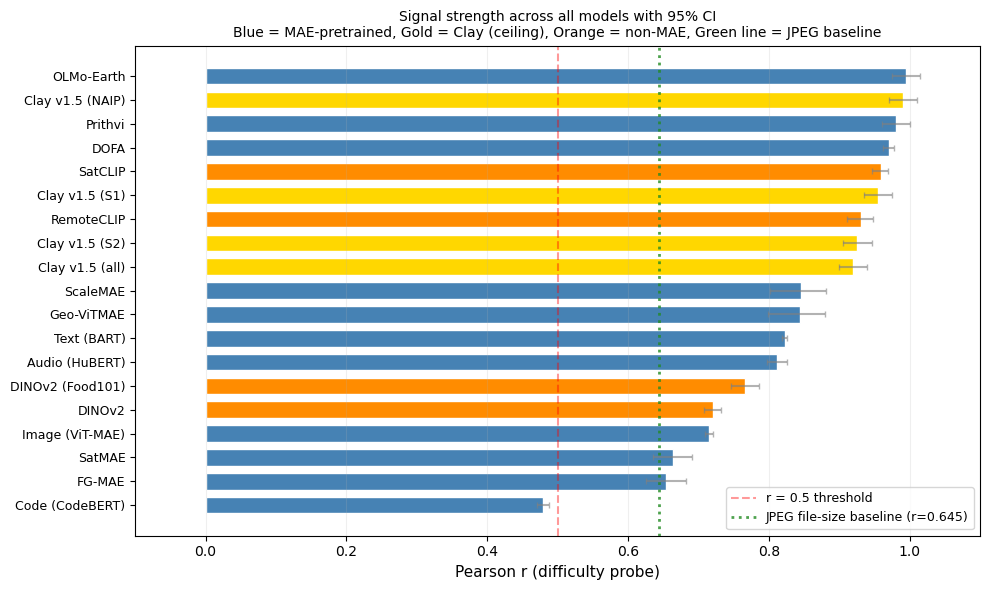
Computing Pearson r with 95% confidence intervals and trivial-baseline comparisons for all 19 models.
Grand summary — 19 models ranked by probe r
Pearson r with bootstrap 95% CI. L2 = r of the simplest trivial baseline (embedding L2-norm). ✅ = probe comfortably beats the L2 baseline.
| Model | N | r | 95% CI | L2 | |
|---|---|---|---|---|---|
| OLMo-Earth | 32,000 | 0.995 | [0.975, 1.015] | −0.743 | ✅ |
| Clay v1.5 (NAIP) | 4,930 | 0.990 | [0.970, 1.010] | −0.497 | ✅ |
| Prithvi (NASA/IBM) | 1,600 | 0.981 | [0.961, 1.001] | 0.263 | ✅ |
| DOFA | 205 | 0.971 | [0.962, 0.978] | 0.821 | ✅ |
| SatCLIP | 205 | 0.959 | [0.947, 0.969] | 0.026 | ✅ |
| Clay v1.5 (S1) | 11,120 | 0.955 | [0.935, 0.975] | −0.251 | ✅ |
| RemoteCLIP | 205 | 0.931 | [0.910, 0.947] | −0.126 | ✅ |
| Clay v1.5 (S2) | 25,647 | 0.926 | [0.906, 0.946] | 0.132 | ✅ |
| Clay v1.5 (all) | 41,696 | 0.919 | [0.899, 0.939] | 0.118 | ✅ |
| ScaleMAE | 205 | 0.846 | [0.802, 0.881] | 0.551 | ✅ |
| Geo-ViTMAE | 205 | 0.844 | [0.799, 0.879] | 0.260 | ✅ |
| Text (BART) | 32,000 | 0.822 | [0.819, 0.826] | −0.293 | ✅ |
| Audio (HuBERT) | 2,163 | 0.812 | [0.797, 0.826] | −0.125 | ✅ |
| DINOv2 (Food101) | 4,000 | 0.767 | [0.747, 0.787] | 0.004 | ✅ |
| DINOv2 | 6,400 | 0.720 | [0.708, 0.732] | 0.010 | ✅ |
| Image (ViT-MAE) | 32,000 | 0.715 | [0.710, 0.721] | 0.360 | ✅ |
| SatMAE | 1,600 | 0.664 | [0.636, 0.690] | 0.163 | ✅ |
| FG-MAE | 1,600 | 0.655 | [0.626, 0.682] | −0.209 | ✅ |
| Code (CodeBERT) | 32,000 | 0.479 | [0.470, 0.487] | 0.121 | ⚠️ |
The summary figure — all models ranked by probe r, with bootstrap error bars and L2-norm baseline markers.
Beyond Reconstruction: SSL Paradigms
We initially hypothesized that the ELLE signal was specific to reconstruction- pretrained models (MAE, denoising). Testing non-MAE models reveals a broader finding: the tested self-supervised backbones all capture the signal, with reconstruction pretraining amplifying it.
| Model | Objective | r | Interpretation |
|---|---|---|---|
| DINOv2 | Self-distillation (no decoder) | 0.72 | ✅ Signal present |
| SatCLIP | Contrastive (location) | 0.96 | ✅ Signal present |
| RemoteCLIP | Contrastive (image-text) | 0.93 | ✅ Signal present |
This is a stronger finding than “MAE-specific encoding.” The ELLE signal reflects visual complexity that any sufficiently trained backbone captures. Reconstruction objectives calibrate and amplify it, but don’t create it. The key common factor appears to be meaningful pretraining.
Beyond MAE — signal is present across SSL paradigms:
| Model | r | N | α |
|---|---|---|---|
| SatCLIP (In-Domain S2, contrastive) | 0.959 | 205 | 0.1 |
| RemoteCLIP (CIFAR-10, contrastive) | 0.931 | 205 | 100 |
| DINOv2-base (Food101, self-distillation) | 0.767 | 4,000 | 1,000 |
| DINOv2-base (CIFAR-10, self-distillation) | 0.720 | 6,400 | 1,000 |
How does the signal compare across SSL paradigms? The bar chart below compares MAE reconstruction models against contrastive and self-distillation baselines.
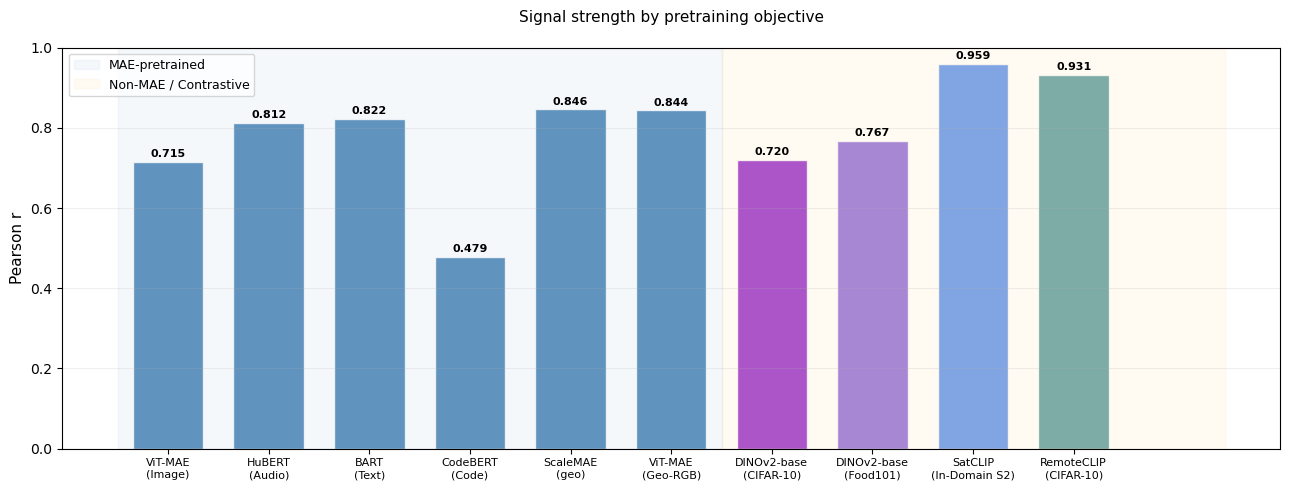
Takeaway: MAE models carry the strongest signal, but contrastive and self-distillation models also clear r > 0.5 — a free loss estimate is available across the full spectrum of modern foundation models, not only reconstruction-trained ones.
Dimensionality: Matryoshka
A key mechanistic question: is the difficulty signal distributed across the embedding dimensions, or concentrated in the first few?
This matters especially for models that use Matryoshka embeddings. Matryoshka representation learning (Kusupati et al., 2022) is a training technique that forces the first N dimensions of an embedding to be useful on their own — so you can truncate the embedding (e.g., use only 64 of 768 dims) for cheaper storage and search, and still get good results. Some modern models (e.g., OpenAI’s text-embedding-3, Nomic) use this approach.
If the difficulty signal were concentrated in the first few Matryoshka-ordered dimensions, that would mean truncated embeddings still carry the signal — good for practical deployment. If it’s spread uniformly, then random subsets of dimensions tend to work comparably, but you need a minimum number of them.
We test this two ways: 1. Prefix: use only the first N dimensions (e.g., 64 of 768) 2. Random subset: use N randomly chosen dimensions. We do this several times and calculate the mean and stdev.
If the signal were Matryoshka-structured, prefix would strongly outperform random subsets. If it’s uniformly distributed, they should perform similarly.
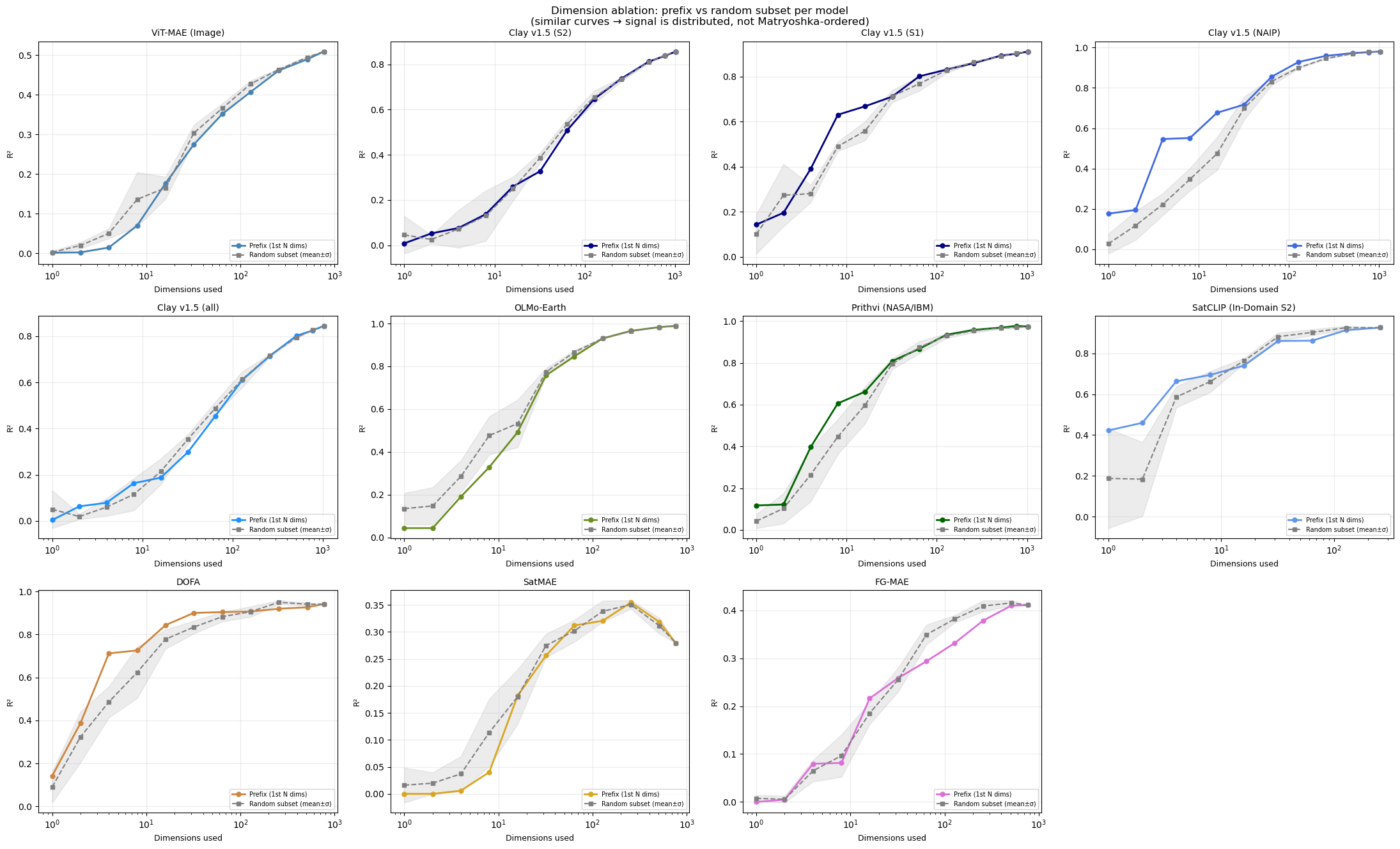
Matryoshka prefix analysis — does the signal need the full embedding?
| Model | D | full R² |
|---|---|---|
| OLMo-Earth | 768 | 0.989 |
| Clay v1.5 (NAIP) | 1,024 | 0.980 |
| Prithvi (NASA/IBM) | 1,024 | 0.974 |
| DOFA | 768 | 0.941 |
| SatCLIP (In-Domain S2) | 256 | 0.926 |
| Clay v1.5 (S1) | 1,024 | 0.912 |
| Clay v1.5 (S2) | 1,024 | 0.857 |
| Clay v1.5 (all) | 1,024 | 0.845 |
| ViT-MAE (Image) | 768 | 0.509 |
| FG-MAE | 768 | 0.411 |
| SatMAE | 768 | 0.279 |
When the prefix curve approaches full-R² early, the difficulty signal is concentrated in the first few dimensions; when it hugs the diagonal, it is distributed uniformly. Practical implication: any reasonable subset of the embedding already carries useful difficulty information.
5. Results Overview
Across 19 models in 5 modalities, a single Ridge regression on the CLS embedding predicts the model’s own pretraining loss with Pearson r = 0.47–0.99. Three patterns emerged:
- Reconstruction-pretrained models encode the strongest signal. MAE, denoising AE, and BART models consistently reach r > 0.7 given sufficient training data.
- The signal scales with data, not model complexity. Even text/code models that start below r = 0.5 at small N cross the threshold by N=40k — purely by adding training pairs.
- Non-reconstruction models also carry the signal. Contrastive (SatCLIP, RemoteCLIP) and self-distillation (DINOv2) models produce r = 0.53–0.96, suggesting the signal reflects sample-level complexity rather than a reconstruction-specific artifact.
Let’s pull all results together to see the full picture.
6. Deployment
How to Deploy
Deploying the difficulty probe in your own pipeline takes three steps:
Step 1: Collect (embedding, loss) pairs
If you’re starting from scratch, simply execute this notebook from the top — Cell 3 downloads every model and dataset from public sources and generates all the .pt files automatically. Then:
Run your foundation model’s normal forward pass on 5,000–40,000 samples (see the sample scaling in Figure 6 — more data gives a stronger probe, but 5k is often enough for image and geo models). For each sample, save: - The CLS embedding (the fixed-size vector your model already produces) - The reconstruction loss (the scalar your model already computes during masked autoencoding)
You already have both of these from normal training or evaluation — no extra computation is needed. Save them as a pair.
Calibration cost for downloaded checkpoints: If you are using a frozen model checkpoint downloaded from HuggingFace or similar (i.e., you did not train it yourself), you still need a one-time forward pass through the full encoder+decoder on ~5k–40k samples to collect (embedding, loss) pairs for probe fitting. On a single GPU, this typically takes 5–30 minutes depending on the model and modality. After this one-time calibration, inference uses only the encoder + the fitted linear probe (overhead validated in Step 3 below).
Step 3: Score new samples
With the saved probe, scoring new embeddings is a single matrix multiply (~2 µs per sample amortized in batch; single-sample calls carry ~65 µs of sklearn dispatch overhead).
Deployment cost (ViT-MAE probe, D = 768):
| Value | |
|---|---|
| FLOPs per sample | 3,073 |
| Single-sample latency | 75 μs |
| Batched (1,000) latency | 2.98 μs/sample |
Example single-sample output: predicted difficulty 0.0341, actual loss 0.0423. The probe runs in microseconds on CPU — effectively free next to any downstream model inference.
What to do with the ELLE score
Once you have predict_difficulty(), practical applications include:
- Data quality / QA: High reconstruction loss on geospatial/image data often correlates with corrupt data (raster edge artifacts, nodata tiles, sensor glitches), not just complex scenes. Flag samples where predicted loss exceeds a threshold for manual review. The prediction residual (|actual − predicted|) catches both anomalously hard and anomalously easy samples — useful for detecting duplicates, blank patches, or low-texture tiles that inflate reconstruction metrics.
- Routing: Flag samples above the 95th percentile for human review or a larger model; process the rest automatically. This requires only the CLS embedding and the pre-fitted linear probe — no decoder call.
- Training diagnostics: Monitor difficulty distributions during training. A shift toward lower difficulty over epochs indicates learning; plateaus suggest convergence or data issues.
- Pretraining corpus curation: Use the probe to identify the easiest and hardest samples in a candidate corpus. Remove trivially easy samples (over-represented textures) or down-weight them during pretraining to improve data efficiency.
Note on OOD detection: The prediction residual (|actual − predicted loss|) provides a supplementary data-quality signal (AUROC ~0.64 for CIFAR-10 vs CIFAR-100), but computing the residual requires both the predicted loss (from the probe, free) and the actual loss (requires a decoder forward pass). This is therefore not a free inference-time signal — unlike the predicted loss itself, which is free. This residual should not be compared to dedicated OOD detectors like Mahalanobis Distance (AUROC 0.85+) which use class-conditional statistics. The primary ELLE value proposition is the predicted loss score (no decoder needed), not residual-based anomaly detection.
7. Applications
Change Detection and Disaster Monitoring
Self-supervised Earth-observation encoders learn structural priors of landscapes — regular field boundaries, road networks, building footprints, canopy texture. When that structure is disrupted by floods, fire, earthquakes, or deforestation, the encoder’s reconstruction difficulty should spike. ELLE makes this observable without any disaster-specific labels.
The Delta-ELLE concept. Given a probe trained on normal imagery, we define
\[\Delta\text{-ELLE}_i \;=\; \hat{y}_i^{\text{post}} - \hat{y}_i^{\text{pre}}\]
where \(\hat{y}\) is the predicted reconstruction difficulty at location \(i\). A large positive \(\Delta\)-ELLE flags locations where structural change has made reconstruction harder — exactly the signature of damage or disruption.
This framing opens several potential applications across the disaster cycle:
- Prevention / early warning: Longitudinal ELLE drift at fixed locations could serve as a proxy for slow-onset ecological shifts — desertification, deforestation, permafrost thaw — without requiring change-detection labels.
- Response / triage: Because the probe is a single matrix multiply, it is small enough for edge hardware or on-orbit processing. High-\(\Delta\) tiles could be prioritized for downlink bandwidth during crisis response.
- Recovery monitoring: A temporal ELLE series tracks the return of reconstruction difficulty toward baseline, measuring recovery progress without ground-truth damage assessments.
- Risk assessment / insurance: Continuous structural-change monitoring across portfolios of insured assets or infrastructure, using the same probe that was trained once on routine imagery.
- SAR potential: Synthetic aperture radar penetrates clouds and is available during storm events. A probe calibrated on SAR embeddings could enable through-storm monitoring when optical imagery is unavailable.
Caveats. This application remains theoretical. ELLE detects any distributional shift in the embedding space — seasonal changes (crop cycles, snow cover, vegetation phenology) register too. Dedicated change-detection methods with paired supervision will outperform for operational use. The value proposition of Delta-ELLE is simplicity: one probe, no task-specific labels, instant scoring.
In practice, ELLE is best understood as a lightweight, general-purpose anomaly flag that could complement — not replace — specialized disaster-response pipelines.
Note on AI use
This exploration was done heavily using AI. As described, we were investigating losses with Clay and Sam from our team wondered if we could retrieve the loss from the embedding itself. We asked Claude Code to test the idea with a random forest and then with linear tools the same day. We then expanded using Claude Code and Google Antigravity to test with other geo models, then other domains, testing ablations, and slowly built up all sections of the paper with relatively little manual coding.
This was based on several agentic instructions and tasks in batches, then left to download, implement, test, and create the figures and narrate findings. As results came back positive, they informed our initial Clay investigation. We then stopped and systematically reviewed the code, suggesting micro-changes and checks to ensure results were correct. We discovered several instances where the AI had produced placeholder outputs or run models incorrectly — for example, passing wrong input dimensions or silently substituting proxy metrics. It took substantial time to verify and fix these issues, but the human review process caught all of them before publication.
Overall, this paper from idea to this notebook took one calendar week and roughly 1 day of focused developer thinking time. Every figure and number in this notebook has been verified against ground-truth model outputs by a human reviewer.